
Elasticsearch 개념을 알아보고 설치해보기!
카테고리: Data-Engineering
대용량의 데이터를 빠르게 검색하고 분석하려면 단순한 데이터베이스로는 부족하다. 이럴 때 사용하는 대표적인 검색 기술이 Elasticsearch다.
Elasticsearch는 로그, 메트릭, 검색 등 대용량 데이터를 다루는 프로젝트에서 빠르고 유연한 검색 시스템이 필요할 때 가장 많이 사용되는 도구다.
1. Lucene(루씬)
🔍 Lucene(루씬)이란?
- 자바로 개발된 오픈 소스 고성능 정보 검색(Information Retrieval, IR) 라이브러리
- IR : 문서를 검색하거나 문서의 내용을 검색하거나 문서와 연관된 메타 정보를 검색해 가는 과정
- 텍스트 데이터의 색인(인덱싱)과 검색에 특화되어 있음
- 루씬은 검색 기능을 갖춘 애플리케이션을 개발할 때 사용하는 소프트웨어 라이브러리
- 루씬은 파일 검색, 웹 문서 수집, 웹 검색 등에 바로 사용할 수 있는 애플리케이션이 아님 => 단독으로 사용 못 함!
루씬의 구조
- 루씬은 색인(Indexing)과 검색(Querying)과정이 있음
- 색인 단계에서는 문서를 Analyzer를 통해 토큰화하고, IndexWriter가 역색인을 생성해 저장
- 검색 단계에서는 사용자의 검색어를 QueryParser가 처리하고, Searcher가 색인된 데이터에서 관련 문서를 찾아 점수 기반으로 정렬된 결과를 반환
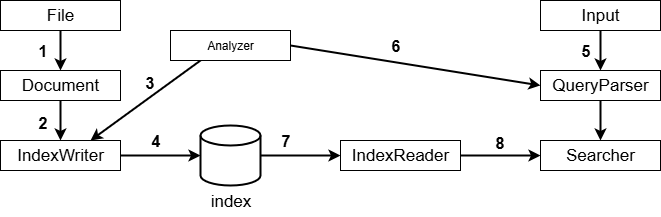
✅ 색인(Indexing) 단계
- 문서를 읽고, 이를 색인하여 검색 가능한 형태로 저장하는 과정
1️⃣ File → Document
- Lucene에서 색인할 대상인 원본 파일을 읽어서, Lucene의 Document 객체로 변환
- 이 Document는 여러 필드(field)로 구성됨
- 예를 들어 title, body, timestamp와 같은 속성을 가질 수 있음
2️⃣ Document → IndexWriter
- IndexWriter는 색인 생성의 핵심 클래스로, 문서를 받아 인덱스에 추가할 준비를 함
3️⃣ Document의 텍스트 → Analyzer
- IndexWriter는 Analyzer를 호출하여 텍스트를 토큰(단어)으로 나눔
- 예: “Elasticsearch is fast” → [“elasticsearch”, “fast”]
4️⃣ IndexWriter → Index
- 분석된 토큰 정보를 Lucene의 역색인 구조로 변환하여 디스크에 저장
✅ 검색(Querying) 단계
- 색인이 완료된 후에는 사용자의 검색어에 따라 관련 문서를 찾아 반환함
5️⃣ Input → QueryParser
- 사용자가 검색창에 입력한 질의 문자열을 받아 Lucene이 이해할 수 있는 쿼리 객체(Query)로 변환
6️⃣ QueryParser → Analyzer
- 검색어도 문서와 동일하게 Analyzer를 거쳐 토큰화
- 문서 분석과 검색어 분석에 같은 분석기를 써야 정확한 비교가 가능함
7️⃣ IndexReader ← Index
- 검색을 위해 저장된 인덱스를 읽어오는 역할
- IndexReader는 색인된 문서를 검색 가능한 형태로 가져옴
8️⃣ IndexReader → Searcher
- Searcher는 Query와 IndexReader를 사용하여 관련 문서를 찾고, 점수를 계산하여 정렬함
- 검색된 결과는 관련도 점수에 따라 정렬됨 (TF-IDF, BM25 등 기반)
- 결과는 사용자에게 반환됨
2. Elasticsearch란
🔍 Elasticsearch란?
- Apache Lucene(아피치 루씬) 라이브러리 기반의 Java 오픈소스 분산 검색 엔진
- 분산 처리, 고가용성, 수평적 확장성 등 엔터프라이즈 영역에 필요한 주요 가능을 제공
- JSON 기반의 문서를 저장, 색인, 검색 가능 => 분산 NoSQL 스토리지 성격을 가짐
- 2013년에는 Elasticsearch의 데이터를 손쉽게 시각화하는 Kibana(키바나), Elasticsearch에 색인할 데이터를 수집하고 변환하는 Logstash(로그스태시)가 등장
- Elasticsearch, Kibana, Logstash를 합쳐 ELK 스택이라고 부름
📌 Elasticsearch의 강점과 특징
- 검색 엔진
- 다른 RDBMS나 NoSQL에 비해 매우 강력한 검색 기능을 지원함
- 단순한 텍스트 매칭 검색이 아닌 전문 검색(full-text search)이 가능하며 다양한 종류의 검색 쿼리를 지원
- 역색인을 사용하여 검색 속도도 매우 빠름
- 다양한 Analyzer를 조합하여 여러 비즈니스 요구사항에 맞는 색인을 구성할 수 있고 형태소 분석도 가능
- 분산 처리
- 데이터를 여러 노드에 분산 저장하며 검색이나 집계 작업 등을 수행할 때도 분산 처리를 지원
- 고가용성 제공
- 엘라스틱서치는 고가용성(High Availability)을 제공
- 클러스터를 구성하고 있는 일부 노드에 장애가 발생해도 복제본 데이터를 이용해 중단 없이 서비스를 지속할 수 있음 -> 이때 엘라스틱서치는 다시 복제본을 만들어 복제본의 개수를 유지하며 노드 간 데이터의 균형을 자동으로 맞춤
- 수평적 확장성
- 서비스를 운영하다 보면 요청 수나 데이터의 양이 증가할 수 있음 => 이런 상황에 대비해서 수평적 확장을 지원
- 더 많은 처리 능력이 필요할 때에는 새로운 노드에 Elasticsearch를 설치하여 클러스터를 참여시키는 것만으로도 확장됨
- 새 노드에 데이터를 복제하거나 옮기는 작업도 Elasticsearch가 자동 수행
- JSON 기반의 REST API 제공
- Elasticsearch에 작업 요청을 보낼 때도 JSON 기반의 REST API를 사용함
- 특별한 클라이언트의 사전 설치 없이도 환경에 구애받지 않고 HTTP를 통해 쉽게 이용할 수 있음
- 데이터 안정성
- 데이터 색인 요청 후
200 OK를 받았다면 그 데이터는 확실히 디스크에 기록됨
- 데이터 색인 요청 후
- 다양한 플러그인을 통한 기능 확장 지원
- Elasticsearch는 다양한 플러그인을 사용해 기능을 확장하거나 변경할 수 있음
- 또한 핵심적인 기능들도 플러그인을 통해 제어할 수 있도록 설계됨
- 엘라스틱이 공식적으로 제공하는 플러그인도 매우 많으며 커뮤니티에서도 다양한 서드파티 플러그인을 공개하고 있음
- 준실시간 검색(near real-time search) 지원
- 데이터를 색인하자마자 조회하는 것은 가능하지만, 데이터 색인 직후의 검색 요청은 성공하지 못할 가능성이 높음
- Elasticsearch가 역색인을 구성하고 이 역색인으로부터 검색이 가능해지기까지 시간이 걸리기 때문
- 기본 설정으로 운영할 경우 최대 1초 정도 시간이 소요
- 따라서 이런 특성을 이해하고 서비스를 설계해야 함
- 트랜잭션이 지원되지 않음
- Elasticsearch는 RDBMS와 다르게 트랜잭션을 지원하지 않음
- 서비스와 데이터 설계 시 이 점을 고려해야 함
- 사실살 조인을 지원하지 않음
- 기본적으로 조인을 염두에 두고 설계되지 않았음
- join이라는 특별한 데이터 타입이 있지만 이는 굉장히 제한적인 상황을 위한 기능이며 성능도 떨어짐
- 기본적으로 RDBMS와는 다르게 데이터를 비정규화해야 함
- 서비스와 데이터 설계에 있어 조인을 아예 사용하지 않는다고 생각해야 함
3. Elasticsearch 설치
(1) Elasticsearch 파일 다운로드하고 실행하기
- 위 링크를 클릭하면 아래와 같은 화면이 나옴 => 플랫폼 선택 후 다운 받기
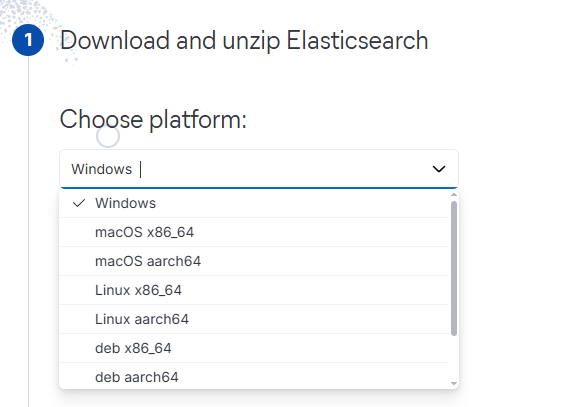
- zip 파일을 원하는 폴더에 압축 해제
- 압축풀고 저장된 경로 알아야 함
- 나는
C:\elasticsearch-9.xxxx저장함
Window 환경
- PowerShell에서 환경 변수 설정
$env:ES_HOME = "C:\elasticsearch-9.xxxx"작성
- 압축을 푼 폴더로 이동한 뒤 bin 폴더에서 PowerShell을 실행
.\elasticsearch.bat입력 후 실행
- 첫 실행 시 초기 비밀번호와 키바나 연결을 위한 토큰 값을 제공함
- 로그에
Password for elastic user .....적힌 부분 찾아서 비민번호 따로 저장해두기 - 비밀번호 있는 근처에
Kibana..........Copy the following enrollment token......부분 찾아서 토큰도 따로 저장해두기
- 로그에
비밀번호를 찾지 못했다면? 비밀번호 초기화를 하라는 말이 많이 나오지만 나의 경우 사용자를 새로 생성해주었음
- PowerShell 또는 CMD에서 다음 경로로 이동:
cd C:\elasticsearch-9.0.3\bin-> 설치 경로로 이동.\elasticsearch-users.bat useradd [생성할 ID] -p [패스워드] -r superuser명령어 실행
- 단, password를 너무 짧게 하면 에러 발생 가능
ERROR: Invalid password...passwords must be at least [6] characters long- elasticsearch 실행 중인 터미널 종료 후 다시 실행하기. (파일 경로로 이동 후 다시 실행)
.\elasticsearch.bat
- Elasticsearch가 잘 설치되었는지 확인해보기
- CMD에서
curl -u admin https://localhost:9200 --insecure했을 때 결과가 나오면 성공
{ "name" : "DESKTOP-DGP06C0", "cluster_name" : "elasticsearch", "cluster_uuid" : "M-RJ5RliR-ePFEgAcL0a-g", "version" : { "number" : "9.0.3", "build_flavor" : "default", "build_type" : "zip", "build_hash" : "cc7302afc8499e83262ba2ceaa96451681f0609d", "build_date" : "2025-06-18T22:09:56.772581489Z", "build_snapshot" : false, "lucene_version" : "10.1.0", "minimum_wire_compatibility_version" : "8.18.0", "minimum_index_compatibility_version" : "8.0.0" }, "tagline" : "You Know, for Search" }- 혹은 브라우저에서
https://localhost:9200하고 설정했던 ID와 Password를 입력한 후에 터미널과 같은 결과 화면이 나오면 성공!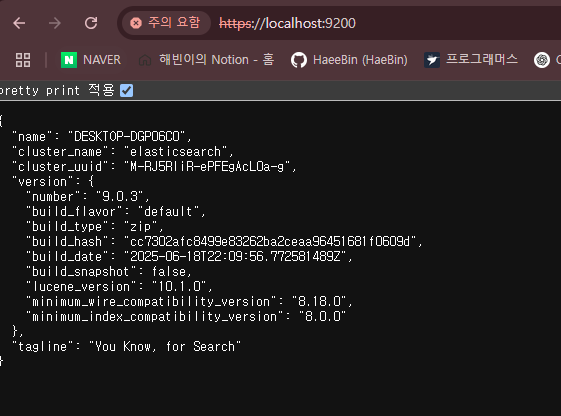
- CMD에서
댓글 남기기