
Airflow 개념 정리
카테고리: Data-Engineering
💡 Airflow는 데이터 엔지니어가 복잡한 데이터 파이프라인을 자동화하고 모니터링할 수 있게 해주는 핵심 도구입니다. DAG로 작업 흐름을 정의하고, Python 코드로 작성한 워크플로를 시각적으로 관리할 수 있습니다.
1. Airflow란?
- Apache Airflow는 초기 에어비엔비(Airfbnb) 엔지니어링 팀에서 개발한 워크플로 오픈 소스 플랫폼
- DAG (Directed Acyclic Graph) 를 기반으로 작업 흐름을 구성
- 작업(Task) 간 의존성, 스케줄, 모니터링, 재시도를 자동화
- Python 코드로 파이프라인을 유연하게 정의 가능
- 즉, 데이터 수집 → 처리 → 저장 등의 과정을 Python 코드로 자동화
- Web UI로 DAG 상태 및 로그 확인 가능
- ETL, 데이터 파이프라인, ML 워크플로 등에 활용
✅ 워크플로(Workflow)란?
- 정해진 순서에 따라 여러 작업을 자동으로 실행하는 작업 흐름
- 반복 작업을 스케줄링하여 정기적으로 실행
- Task 간 의존성을 고려하여 순차 또는 병렬 실행 가능
- 예시:
- 데이터 수집 → 전처리 → DB 적재 → 리포트 생성 → Slack 공유
2. 왜 Airflow를 사용할까?
- 데이터 엔지니어링에서 가장 자주 하는 일은 데이터를 정해진 순서로 수집하고, 가공하고, 저장하는 것 => ETL(Extract, Transform, Load)
- 이를 매일, 시간마다, 조건이 맞을 때마다 자동으로 실행되게 하려면 강력한 워크플로 관리 도구가 필요
👉 단순한 cron이나 스크립트 자동화로는 의존성 관리, 오류 재시도, 로그 추적이 어렵고 확장성도 떨어집니다.
✅ 그중에서도 왜 Airflow인가?
- 복잡한 데이터 파이프라인의 자동화와 관리
- Airflow는 여러 단계로 이루어진 데이터 파이프라인을 원하는 순서와 시점에 자동으로 실행할 수 있음
- 각 작업(Task) 간의 의존성을 명확하게 정의하고, 순차적 혹은 병렬 실행이 가능
- DAG(Directed Acyclic Graph) 기반 설계
- 작업의 흐름과 의존성을 DAG로 시각적으로 표현할 수 있어, 파이프라인 구조가 명확해지고 관리가 쉬워짐
- 파이썬 코드로 유연하게 파이프라인 정의
- 파이썬의 프로그래밍적 유연성을 활용해 복잡한 로직, 조건, 반복 등을 자유롭게 구현 가능
- 강력한 스케줄링과 모니터링
- 크론 스타일의 스케줄러와 웹 UI를 통해 파이프라인 실행 현황을 한눈에 파악하고, 실패 시 자동 재시도·알림 등 운영 편의성이 뛰어남
- 확장성 및 다양한 시스템 연동
- AWS, GCP, Hadoop, Spark 등 다양한 외부 시스템과 쉽게 연동할 수 있고, 대규모 병렬 처리가 가능
- 운영 효율성
- 실패한 작업만 재실행하거나, 부분적으로 데이터를 다시 처리하는 등 운영자의 부담을 크게 줄여줌
3. Airflow 주요 구성 요소
(1) Webserver
- 사용자에게 제공되는 웹 UI 인터페이스
- Airflow의 Metastore 저장된 로그를 보여주거나 스케쥴러에 의해 파싱된 DAG들을 시각화해서 제공
- 수동 실행, 재시도, DAG 비활성화 등의 제어 기능 제공
- 운영자가 DAG 상태를 모니터링하거나 오류를 디버깅할 때 핵심적인 창구
(2) Scheduler
- DAG 파일을 주기적으로 스캔(분석)하고, 실행 스케줄에 맞춰 DAG을 트리거
- Task들을 Executor에 전달하여 실행 요청
- DAG 파일의 변경 사항을 감지하고 메타데이터 DB에 반영
- Airflow의 “심장” 역할
(3) Executor
- Task를 어떤 방식으로 실행할지 결정하는 실행 전략 컴포넌트
- 종류에 따라 Task 실행 구조가 달라짐
SequentialExecutor: 순차 실행 (개발/테스트용)LocalExecutor: 병렬 처리 (단일 머신)CeleryExecutor: 다중 Worker 분산 처리KubernetesExecutor: K8S 환경에서 Pod 기반 Task 실행
(4) Worker
- 실제로 Task를 실행하는 프로세스
- Scheduler가 Executor를 통해 Task를 전달하면, Worker가 실행
CeleryExecutor,KubernetesExecutor를 사용하는 경우 반드시 분리 운영- 병렬성, 확장성, 작업 격리를 위해 중요한 역할
✅ Airflow의 구성도
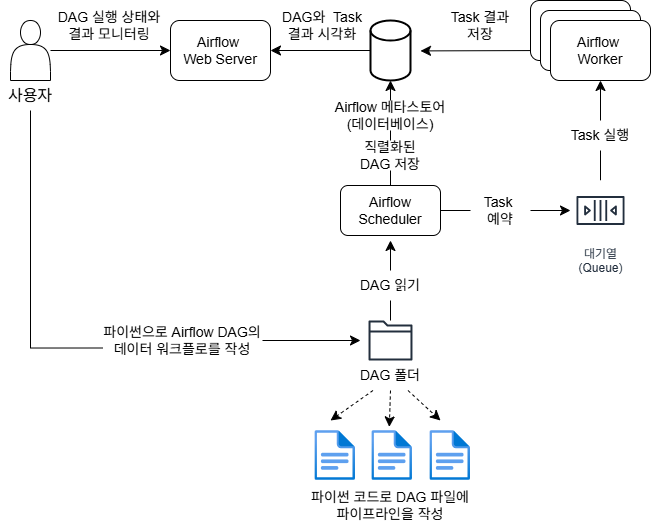
이미지에 나와 있는 Apache Airflow 구성도의 동작 순서는 다음과 같습니다[1]:
- DAG 작성
- 사용자가 파이썬 코드로 Airflow DAG(워크플로우)를 작성함.
- 작성된 DAG 파일은 DAG 폴더에 저장됨.
- DAG 폴더 감지
- Airflow Scheduler가 DAG 폴더를 주기적으로 읽어 새로운 DAG 파일이나 변경된 DAG 파일을 감지
- DAG 읽기 및 예약
- Scheduler는 DAG 파일을 읽고, 실행 조건에 따라 실행해야 할 Task를 예약(Queue)에 등록
- Task 실행
- 예약된 Task는 대기열(Queue)에 들어가고, Airflow Worker가 이를 받아 실제로 Task를 실행
- Task 결과 저장
- Worker는 Task 실행 결과를 Airflow 메타스토어(데이터베이스)에 저장
- 상태 및 결과 시각화
- Airflow Web Server가 메타스토어의 정보를 바탕으로 DAG와 Task의 실행 상태 및 결과를 시각화하여 사용자에게 제공
- 모니터링
- 사용자는 Web Server를 통해 DAG 실행 상태와 결과를 모니터링할 수 있음.
정리된 표
| 단계 | 설명 |
|---|---|
| 1 | 사용자가 파이썬 코드로 DAG 작성, DAG 폴더에 저장 |
| 2 | Scheduler가 DAG 폴더를 읽어 DAG 감지 |
| 3 | Scheduler가 실행할 Task를 예약(Queue 등록) |
| 4 | Worker가 예약된 Task를 받아 실행 |
| 5 | Worker가 실행 결과를 메타스토어(DB)에 저장 |
| 6 | Web Server가 실행 상태와 결과를 시각화하여 사용자에게 제공 |
| 7 | 사용자가 Web Server에서 실행 상태와 결과를 모니터링 |
✅ Airflow의 동작과정
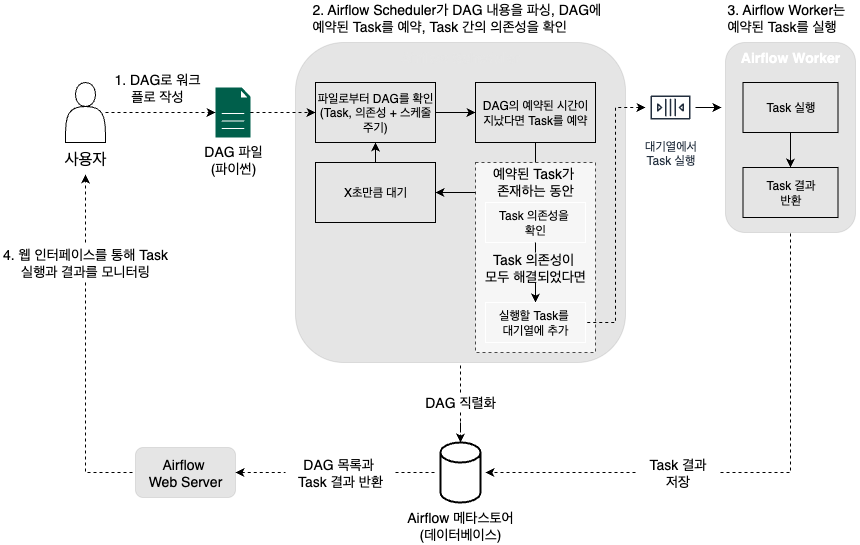
- DAG 작성 및 등록
- 사용자가 파이썬으로 DAG 파일을 작성해 Dags 폴더에 저장
- DAG 파싱 및 인식
- Web Server와 Scheduler가 Dags 폴더의 DAG 파일을 파싱해 DAG 정의를 읽어옴
- DAG 실행 인스턴스 생성
- Scheduler가 메타스토어(데이터베이스)를 통해 해당 DAG의 실행 인스턴스(DagRun 오브젝트)를 생성
- DagRun은 실제 실행 중인 DAG의 상태를 나타내며, 처음에는 Status가 Running
- Task 인스턴스 스케줄링
- Scheduler는 DAG 내 각 Task의 인스턴스(Task Instance)를 생성하고, 실행 조건이 충족되면 스케줄링함
- Task 실행 트리거
- 실행 조건이 맞으면 Scheduler가 Task Instance를 Executor로 전달
- Task 실행
- Executor(및 Worker)가 Task Instance를 실제로 실행
- 실행 결과 저장 및 상태 업데이트
- 실행이 완료되면 결과가 메타스토어에 저장되고, 해당 Task Instance의 상태가 업데이트
- 모든 Task가 완료되면 Scheduler는 DagRun의 상태를 Completed로 변경합니다.
- 결과 모니터링
- 메타스토어의 상태 변화가 Web Server에 반영되어, 사용자가 웹 UI를 통해 전체 실행 현황과 결과를 실시간으로 확인
4. Airflow의 장단점
(1) 장점
- 작업 간 의존성을 코드로 명확하게 정의할 수 있고, 순차 실행과 병렬 실행 모두 지원
- 반복되는 데이터 작업을 코드로 관리해 가독성과 재현성을 높임
- 스케줄링, 재시도, 실패 시 알림 등 자동화 기능을 기본 제공
- 실행 상태와 로그를 웹 UI에서 시각적으로 확인할 수 있어 운영이 편리함
- 데이터베이스, API, Slack 등 다양한 시스템과 연동 가능한 Operator를 기본 제공
- 파이썬 기반이라 복잡한 로직도 쉽게 구현 가능
- 오픈소스라 무료로 사용할 수 있고, 커뮤니티가 활발해 자료와 플러그인이 풍부함
(2) 단점
- 사용법과 개념이 복잡해 초보자에게 어려움
- 실시간(Streaming) 처리에는 부적합
- 초단위 처리, 스트리밍 파이프라인은 Flink, Kafka 등 별도 도구가 적합
- Airflow는 반복적이고 배치 중심의 워크플로우에 최적화됨
- 대규모 데이터 처리에 성능 한계
- Airflow 자체는 데이터 처리용이 아님 → Spark 등 외부 처리 프레임워크 필요
- 예: SparkSubmitOperator로 Spark 작업 분리 수행
- 워커 간 코드 동기화 및 로그 관리가 번거로움
- Airflow를 여러 대의 서버(워커)에서 운영할 때, 모든 워커가 같은 DAG(코드)를 항상 갖고 있어야 함
- DAG 파일이 바뀌면 모든 워커에 똑같이 배포해야 하며, 작업 로그도 여러 서버에 분산되어 저장되기 때문에, 로그를 한 곳에서 모아 보거나 관리하려면 추가 설정이 필요
- DAG가 커질수록 코드 복잡도 증가
- 의존성 관리, 조건 분기 등이 복잡해지고 유지보수 부담 증가
- DAG 버전 관리 기능 부족
- 코드 변경 이력 추적이 어려움 (Airflow 3부터는 DAG 버전 관리 기능이 추가됨)
- 설치 및 운영 난이도 높음
- Airflow는 Webserver, Scheduler, Worker, DB 등 여러 구성 요소 필요
- 확장 시 인프라 및 설정 관리 부담 증가
댓글 남기기